
Natural Language Processing

This testimonial comes from a user who improved the predictive power and model size of BERT models across a wide spread architecture settings and two datasets. BERT, a model released by Google, is often considered one of the original LLMs. It is still widely used today when parameter and training time efficiency is too important to use a larger LLM.
Evan Davis is the CTO and co-founder of Skim AI Technologies, an AI as-a-service firm founded in 2017 and headquartered in New York City. The company specializes in providing custom artificial intelligence and machine learning solutions to help businesses optimize operations and make better decisions using their data.
Since 2019, Evan has been building information classification and extraction pipelines based on the Bidirectional Encoder Representations from Transformers (BERT) model architecture, which is a pre-trained deep learning language model that can be fine-tuned for specific tasks. Even in the age of Large Language Models (LLMs), BERT is still a powerful tool that is competitive in efficiency and performance.
"Our experiments with Perforated AI's Perforated Backpropagation™ technology showed consistent improvements across all model architectures we tested. When applied to BERT-based classification models trained on standard benchmark datasets, we observed accuracy improvements ranging from 3.3% to 16.9% with only 0.01% additional parameters.
The data clearly demonstrates that Perforated Backpropagation is particularly effective for smaller models, allowing us to achieve comparable accuracy to larger architectures while maintaining significantly lower parameter counts. For example, a bert-tiny "Deep Summing Network" model with no self-attention layers (497K parameters) reached an accuracy of 86.5%, outperforming the standard bert-tiny model (4.3M parameters) that achieved 86.3% — a minor reduction in error, but with only 11.3% as many parameters.
The DSN architecture replaces the computationally expensive self-attention mechanism with simple sum pooling, resulting in 15x faster inference speeds. Without PB, DSNs would typically be limited to applications where speed was more critical than accuracy, but with Perforated Backpropagation, these networks become viable for a much broader range of edge and resource-constrained applications where both performance and efficiency matter.
What impressed us most was how quickly we were able to implement and scale the technology. In just one week of experimentation, we had it working effectively across numerous variations of BERT models. After initially dialing in optimization parameters like learning rate on a smaller model and dataset, we were able to scale up to larger models and datasets with minimal adjustments. The seamless integration with HuggingFace made the entire process straightforward, requiring only minor code changes while maintaining full compatibility with HF models. This ease of implementation means teams can quickly adopt this technology and start seeing improvements without significant development overhead."
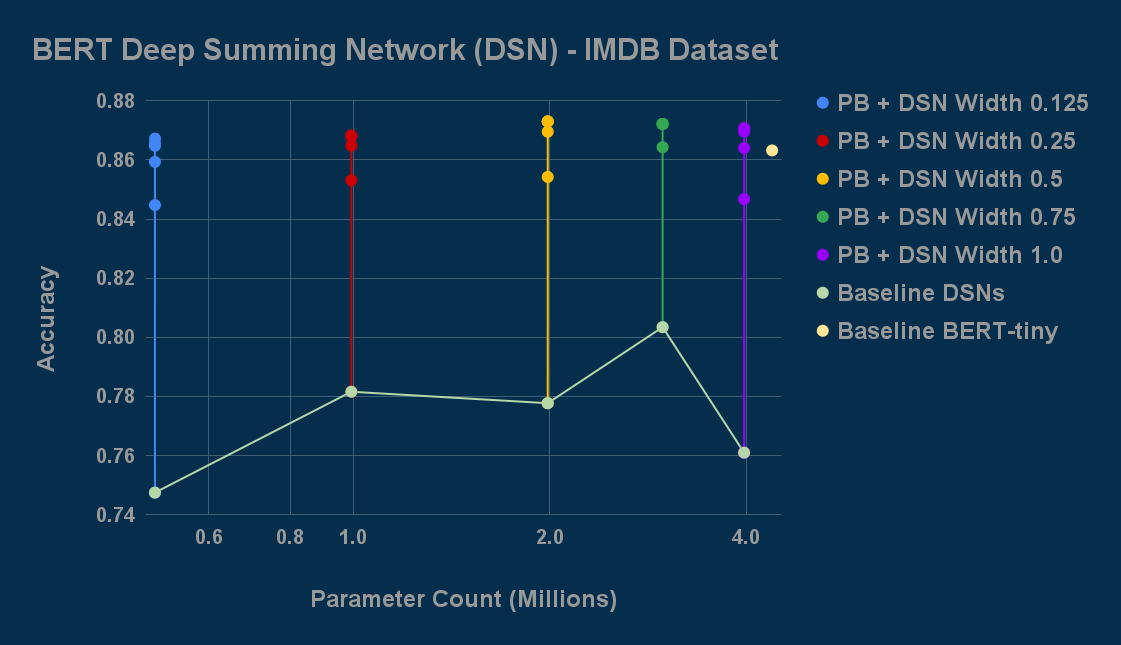
Adding PB across multiple model sizes allows BERT-DSN networks to catch up to and beat a BERT-tiny model, which originally scored higher, while maintaining nearly 90% fewer parameters on the IMDB Dataset.
“Our experiments with Perforated AI’s Perforated Backpropagation™ technology showed consistent improvements across all model architectures we tested.
- - -
What impressed us most was how quickly we were able to implement and scale the technology. In just one week of experimentation, we had it working effectively”

Adding PB across many architectures and model sizes consistently improved accuracy on the SNLI Dataset.