
Everyone is talking about making LLMs bigger and more powerful. But what if you could make them smarter and greener instead?
That's exactly what happened when cutting-edge Perforated BackpropagationTM was applied to GPT-2, one of the foundational large language models (LLMs) that sparked the AI revolution.
The results? A 16% improvement in error reduction without adding any extra parameters to the model. Let that sink in: better performance, same model size, less computational overhead.
The Challenge
The General Language Understanding Evaluation (GLUE) benchmark is a collection of resources for training, evaluating, and analyzing natural language understanding systems. It is a comprehensive evaluation suite that has become the standard for measuring LLM performance.
OpenAI, Anthropic, Google, and other AI giants are locked in an intense race for every fraction of a percentage point on these benchmarks. When you're scaling models to hundreds of billions of parameters and serving millions of users, even a 1% improvement would enable tens of millions of dollars in savings on compute and infrastructure. The traditional economics are brutal: better performance traditionally means bigger models, which means exponentially higher costs.
This is where Parameter-Efficient Fine-Tuning (PEFT) enters the picture. PEFT techniques allow you to adapt LLMs to specific tasks while training only a tiny fraction of their parameters. It's critical for deployment at scale, but even PEFT has limitations.
Until now.
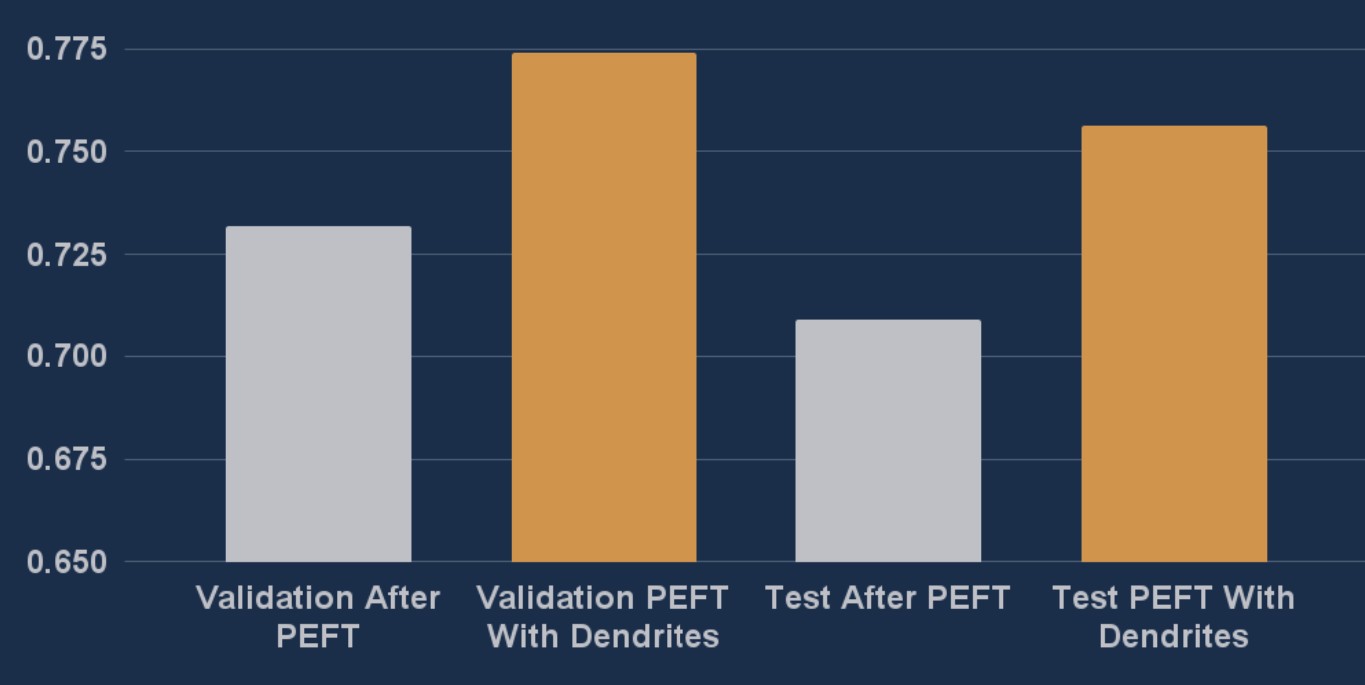
The Breakthrough: Making Efficient Training Even Better
Integration of Perforated BackpropagationTM with the LoRA layers in Hugging Face's PEFT library produced substantial improvements. Across 5 separate cases, adding dendrites to the LoRA layers achieved 16% better error reduction compared to training LoRA layers alone, demonstrating consistent performance gains while maintaining the parameter efficiency advantages.
Real-World Impact
These improvements show that Perforated BackpropagationTM is symbiotic with other parameter-efficient optimization training methods. For teams deploying language models at scale, this means better performance without the computational overhead of full fine-tuning, enabling more capable models on edge devices and reducing infrastructure costs.
Think about what this means:
- Edge devices that can run more capable LLMs
- Smaller companies competing with tech giants on model performance
- Dramatically reduced infrastructure costs for AI deployment
- The same environmental footprint, but with smarter models
Why This Matters
We're at an inflection point in AI. The era of "just make it bigger" is colliding with the reality of computational limits, energy costs, and the need to deploy AI everywhere from smartphones to satellites.
Perforated BackpropagationTM represents a different path forward: optimization over expansion, intelligence over size, efficiency over brute force.
This isn't just an incremental improvement. It's a fundamental rethinking of how we train neural networks—one that makes advanced LLM capabilities accessible to everyone, not just those with hyperscale data centers.
The future of LLMs isn't just about making them larger. It's about making them smarter, more efficient, and more accessible. And that future is already here.
Ready to Optimize Your Models?
See how Perforated BackpropagationTM can improve your neural networks
Get Started Today